
豆包这个AI,不同环境使用,推荐的内容也不一样啊?
如题,谷子发现,在不同的终端上,发送相同的问题问豆包,给的结果竟然也不一样。甚至同一个设备,发送同样的问题,给的结果也不相同。
这点就很奇怪了啊。
原因是询问的问题是"甲骨文云Oracle 春川有那些IP段, 那个IP段网络较好", 众所周知,因为甲骨文云上月对线路调整后,春川数据中心的云主机再回巅峰,又因为离内地距离原因,到国内的访问速度相当的快。
但是在实际应用中,测试不同的IP确实延迟均不相同,想着现在的AI都是到处抓取内容做分析然后展示,结果应该比较客观,然后结果让人更加头晕了。不同的设备,获取到的资讯和内容都不尽相同,以甲骨文云的节点来讲,一个终端极其推荐185.212.X.X段,另外一个终端强烈推荐144.221.X.X段。
同样一个146.56段,一个说是“综合王”(SDS+SK接入),另外一个说是“中端偏下”(SK接入),对于144.24.X.X段,两次的评价也不相同。


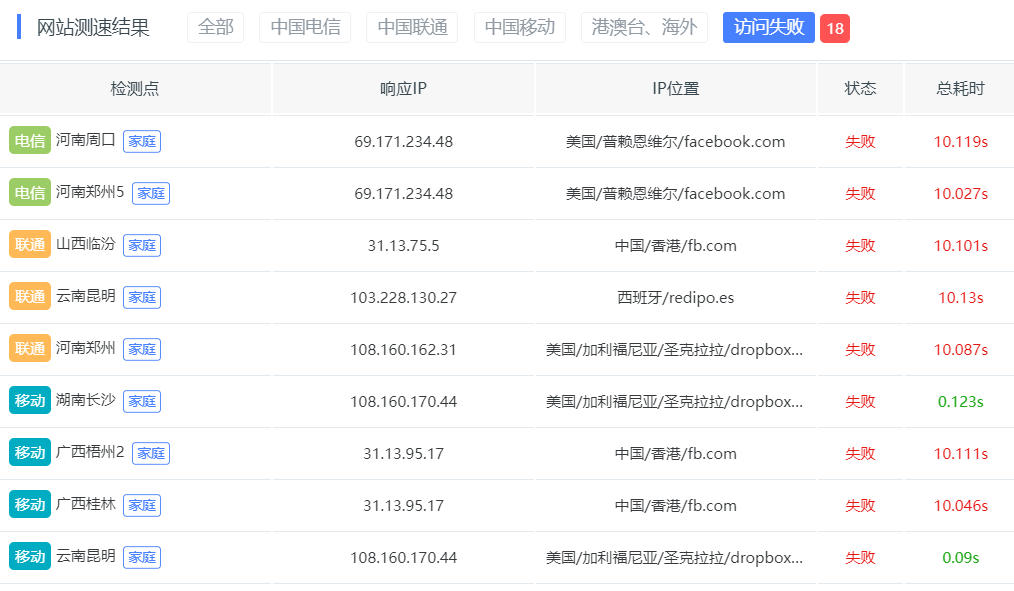
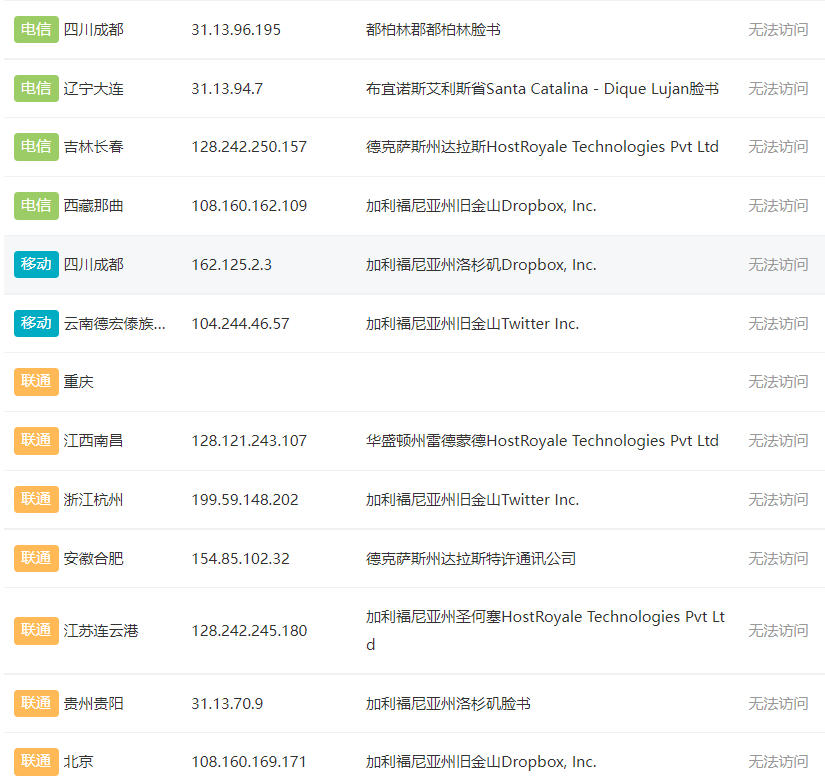
当然在谷子自己的测试当中,虽然同属甲骨文云,同属春川机房。不同的IP段测速的时候,能达到的速率并不一样,在上海那样的国际互联汇入点可能不太明显,在湖北测试,发现延时和速率差距还是比较大的。
另外发现ARM机子所属的IP段,可能之前统一做了限速(免费号均限速到50M),网络条件比AMD的实例好一些。
当然还是建议自己实测一下,甲骨文云免费账户可以开通2个AMD实例(2C+1G+50G X2), ARM实例(4C + 24G +100G)(ARM的实例累计不能超4C 24G内存,但可以拆开,账户所属数据中心硬盘不能超200G),意思至少可以开通3个实例并获取不同的IP做测试。
实际使用中,谷子发现156.46段和144.24段网络均可以。
这件事情也可以看出,豆包等AI的结果也不是很权威的,因为采样的不同,得出的结果也不相同,也就能看出当样本的数量足够,像这种基于各种采集参考AI给出的结果很显然能被影响。
最后回到VPS上,具体的实例还是自行检测要好一些,推荐一键检测脚本:
https://www.xgiu.com/onekey_vpstest








发表评论